# 🍭🍭欢迎各位友友来 我后院 (建设中) 里踩踩🍭🍭
📢 声明:
转载,请先标注出处哦!编写不易,尊重一下劳动成果哦!
个人博客网站 ==》https://alicewanttobackuw.github.io/
github ==》https://github.com/AliceWantToBackUw
csdn ==》https://blog.csdn.net/lengyue29
📢 更新说明:2024-02-18 14:55:10
由于用于 cdn 加速的staticaly.com域名过期,移至新域名statically.io,导致图片无法加载,现已修复
# 🤖医疗诊断文本多分类问题(NLP)(合工大机器学习)
# 📢 说明
完整代码和相关资源在本人 github 上。(论文就不放了哈,史老师应该教了你们怎么写)
# ❓ 问题引入
附件 gastric.xlsx 是包含 5 类的病理诊断文本报告数据集,请完成以下任务:(1)使用 1 种非深度学习算法和至少 2 种深度学习算法完成文本分类,介绍算法原理并评估算法性能;
先检查附件,共 250 条数据,并且高度相关
# 🧠方法决策
对于自然语言文本分类问题的处理的常用算法有很多。
非深度学习算法: K-近邻算法 、 朴素贝叶斯算法 、 决策树 以及 集成学习方法之随机森林 等。
深度学习算法: TextCNN 、 FastText 、 DPCNN 、 TextRNN 、 TextRCNN 以及 Bert 等。
本题中,非深度学习算法,我采用随机森林算法;深度学习算法,我采用 TextCNN 和 FaxtText。
# ⚙传统机器学习方法中:
K-近邻算法,虽然简单,易于理解,易于实现,还无需训练,但缺点很明显,它是一种懒惰算法,对测试样本分类时的计算量大,内存开销大,而且还需要手动指定 K 值, K 值选择不当则分类精度不能保证。朴素贝叶斯算法,虽然也比较简单,分类准确的较高,速度还比较快,但却有个较大的缺点,该算法由于使用了样本属性独立性的假设,所以如果特征属性有关联时其效果不好。由于我需要处理的是医疗诊断文本,其中有很多专业词是高度关联的,因此也不太适合。决策树,通过信息增益等方法来进行作为分类依据,它的效果就明显,准确率高,不过最大的缺点就是,容易出过拟合。随机森林算法,控制森林的高度和森林中树木的数量,确保准确率的同时有效防止过拟合。由于森林的高度和树木的数量属于超参数,所以我再加上一个网格搜索,实现自动调参,选择最合适的超参数,作为模型。
因此我选择采用 随机森林算法
# ⚙深度学习方法中:
TextCNN,一听到 CNN 就会联想到图像处理邻域。而 TextCNN 创新之处就在于,通过将卷积神经网络 CNN 应用到文本分类任务中,利用多个不同 size 的 kernel 来提取句子中的关键信息。从而能够更好地捕捉局部相关性。与传统图像的 CNN 网络相比,textCNN 在网络结构上没有任何变化 (甚至更加简单了)。虽然 TextCNN 网络结构简单,但在模型网络结构如此简单的情况下,通过引入已经训练好的词向量依旧有很不错的效果,在多项数据数据集上超越 benchmark。所以,我选用了 TextCNN 算法。FastText,FastText 是 Facebook 于 2016 年开源的一个词向量计算和文本分类工具,在学术上并没有太大创新。但是它的优点也非常明显,在文本分类任务中,FastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。在标准的多核 CPU 上, 能够训练 10 亿词级别语料库的词向量在 10 分钟之内,能够分类有着 30 万多类别的 50 多万句子在 1 分钟之内。FastText 的核心思想: 将整篇文档的词及 n-gram 向量叠加平均得到文档向量,然后使用文档向量做 softmax 多分类。这中间涉及到两个技巧:字符级 n-gram 特征的引入以及分层 Softmax 分类。而且,官网给的文档还有指定时间自动调优的方法,所以我选用了 FastText 算法。
📕参考自黑马讲义文档:
阿里云盘:密码 6h3j
# 🥊开始实战
# 🔑随机森林算法
最开始导包
import pandas as pd
import jieba as jb
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
import joblib首先,获取数据,加载停用词(注意:读取
.xlsx文件需要指定openpyxl)# 1、获取数据all_pd_data = pd.read_excel(io="../src/gastric.xlsx", engine="openpyxl")
# * 加载停用词with open('../src/stop_words.txt', 'r',
encoding="utf-8") as f:
stop_words = list(l.strip() for l in f.readlines())
# 由于停用词中没有 '\n' 和中文的左右括号和空格,所以单独再加上去stop_words.extend(['\n', '(', ')', ' '])
其次,对数据进行预处理,对中文文本进行分词,随机划分训练集和测试集(注意:按照
Label分层抽样,确保训练集和测试集样本均匀)# 2、数据预处理# * 对中文文本进行分词all_pd_data['Pre_Text'] = all_pd_data['Text'].apply(
lambda x: " ".join([w for w in list(jb.cut(x)) if w not in stop_words]))
# * 划分训练集和测试集 (按照 Label 采用分层抽样,保证训练集和测试集样本均匀)file_txt_train, file_txt_test = train_test_split(all_pd_data, test_size=0.2, stratify=all_pd_data['Label'])
然后,进行特征工程,使用
tf-idf进行提取特征,再通过PCA进行降维,剔除相关性较大的特征# 3、特征工程# * 3.1、求出训练集 tf-idf# * 3.1.1、实例化一个转换器类transfer = TfidfVectorizer(stop_words=stop_words)
# * 3.1.2、调用 fit_transformx_train = transfer.fit_transform(file_txt_train["Pre_Text"])
x_test = transfer.transform(file_txt_test["Pre_Text"])
x_train_feature = transfer.get_feature_names()
x_train = x_train.toarray()
x_test = x_test.toarray()
y_train = file_txt_train["Label"].tolist()
y_test = file_txt_test["Label"].tolist()
# print ("文本特征抽取的结果:\n", x_train.toarray ())# print ("返回特征名字:\n", transfer.get_feature_names ())# * 3.2、通过 PCA 降维# * 3.2.1、实例化一个转换器类 PCAtransfer = PCA(n_components=80)
# * 3.2.1、调用 fit_transformx_train = transfer.fit_transform(x_train, x_train_feature)
x_test = transfer.transform(x_test)
# * 3.3、准备超参数param_grid = {
"n_estimators": [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000],
"max_depth": [5, 8, 15, 25, 30]
}# x_train.shape # (200, 80)接着,构建随机森林模型。
cv的次数自己根据电脑情况调节。# 4、构建随机森林模型estimator = RandomForestClassifier()
estimator = GridSearchCV(estimator=estimator, param_grid=param_grid, cv=3)
# 开始训练estimator.fit(x_train, y_train)
# * 保存模型joblib.dump(estimator, "./随机森林模型.pkl")
最后,加载模型并通过绘图评估模型
# 5、评估模型# * 加载模型estimator = joblib.load("./随机森林模型.pkl")
# * 进行预测y_predict = estimator.predict(x_test)
# 计算准确率score = estimator.score(x_test, y_test)
print("准确率:\n", score)
# 查看最佳参数,最佳结果,最佳估计器print("查看最佳参数:\n", estimator.best_params_)
print("最佳结果:\n", estimator.best_score_)
# * 绘图results = pd.DataFrame(estimator.cv_results_)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 显示中文标签
plt.figure(figsize=(15, 6))
plt.subplot(121)
plt.xlabel('n_estimators')
plt.ylabel('mean_test_score')
each_length = len(param_grid.get("n_estimators")) # 每次森林树木数量的种类
for i in range(len(param_grid.get("max_depth"))):
plt.plot(param_grid.get("n_estimators"), results["mean_test_score"].tolist()[i * each_length:(i + 1) * each_length],
label="max_depth: " + str(param_grid.get("max_depth")[i]))
plt.legend()
plt.subplot(122)
scale_ls = range(1, 6)
plt.title(f"best_params: \n"
f"max_depth: {estimator.best_params_.get('max_depth')} "f"n_estimators: {estimator.best_params_.get('n_estimators')}\n"f"acc: {score}", fontsize=20)
index_ls = ['__label__1', '__label__2', '__label__3', '__label__4', '__label__5']
plt.yticks(scale_ls, index_ls) ## 可以设置坐标字
plt.plot(y_test, color="red", marker='o', label="真实分类")
plt.plot(y_predict, color="blue", marker='.', label="预测分类")
plt.xlabel("样本", fontsize=14)
plt.ylabel("分类", fontsize=14)
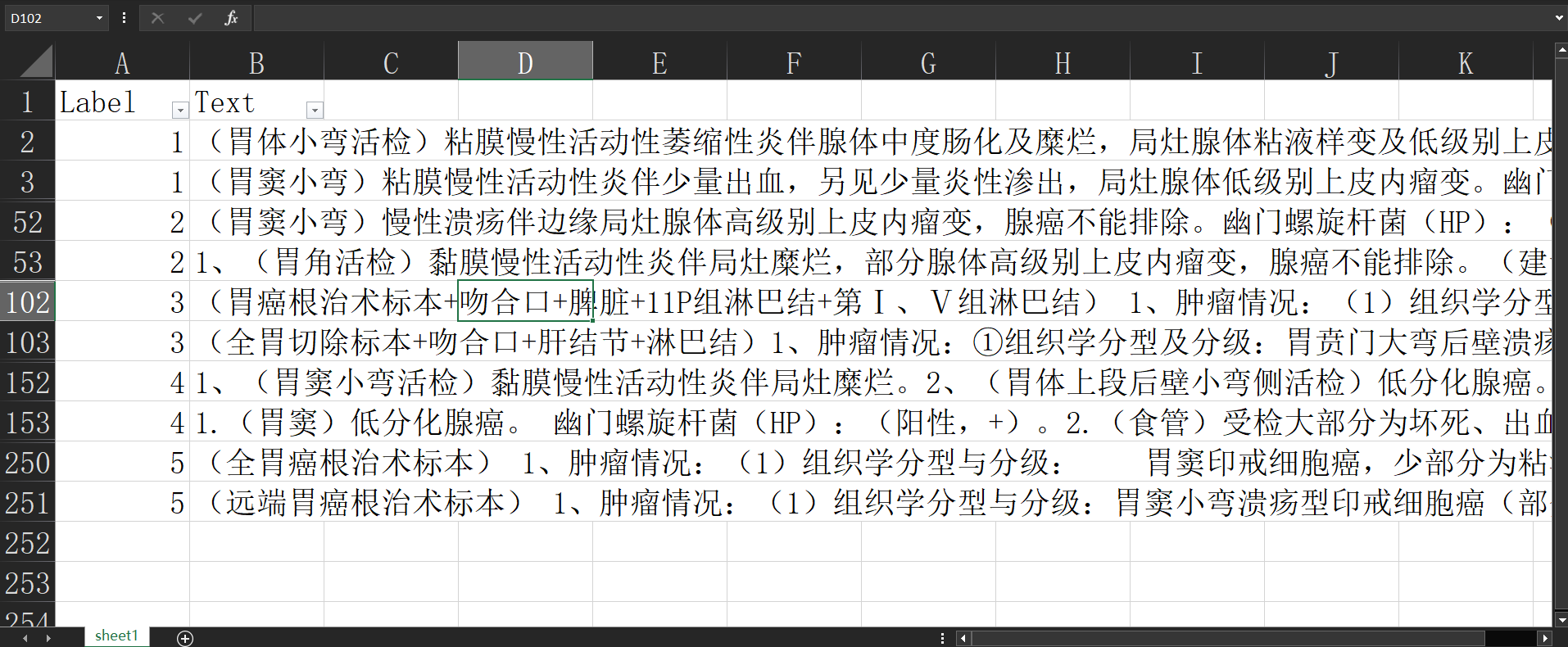
从图中可以看出,在测试集上的 准确率:0.76 。
此时模型最优的模型参数是,森林的最大高度: 8 ;森林的树木数量: 400
而且,经过多次运行,发现测试集上的准确率并不稳定,浮动较大。怎么说咧,结果还是差强人意。不过,毕竟只有 250 条数据,使用非深度学习方法能达到这样,还行。
# 🔑TextCNN
** 前提:** 本算法使用了
tensorflow-gpu,配置好了GPU
tensorflow 学习视频:神经网络与深度学习 —TensorFlow 实践_中国大学 MOOC (慕课)
同样首先,导包
import pandas as pd
import jieba as jb
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
接着,同样先获取数据,设置一下
GPU,并按照Label采用分层随机抽样# 1、获取数据excel = '../src/gastric.xlsx'
# 使用 pandas 读取 excel 数据,需要指定 engine 为 openpyxl(需先要下载 openpyxl)file_txt = pd.read_excel(excel, engine="openpyxl") #[250 rows x 2 columns]
# * 配置 GPU# 打印 tensorflow 版本信息 # 2.10.0 2.10.0print(tf.__version__, tf.keras.__version__)
# 获取 gpugpus = tf.config.experimental.list_physical_devices('GPU')
# 允许 gpu 内存增长(我只有一个 GPU, 多个 GPU 使用循环配置)tf.config.experimental.set_memory_growth(gpus[0], True)
# 1.2、划分训练集和测试集(按照 Label 采用分层抽样,保证训练集和测试集样本均匀)file_txt_train, file_txt_test = train_test_split(file_txt, test_size=0.2, stratify=file_txt['Label'])
然后,对文本进行预处理。先加载停用词,分词,接着将词映射为整数。
** 映射为整数的思路:** 先把每一个样本分词,取分词最多的样本的词数量作为最大的词长度,对没有达到的样本,进行末端补0操作(因为输入卷积模型的词向量的长度需要保持一致)
获取tokenizer尤其注意,需要加一个未知词<UNK>。
还需要注意:使用num_class,标签值中的最大数加1# 2、对 text 文本进行预处理# 2.1、加载停用词with open('../src/stop_words.txt', 'r',
encoding="utf-8") as f:
stop_words = list(l.strip() for l in f.readlines())
stop_words.extend(['\n', '(', ')', ' ']) # 由于停用词中没有 '\n' 和中文的左右括号和空格,所以单独再加上去
# 2.2、对训练集和测试集分词,并去除停用词file_txt_train['Pre_Text'] = file_txt_train['Text'].apply(
lambda x: " ".join([w for w in list(jb.cut(x)) if w not in stop_words]))
file_txt_test['Pre_Text'] = file_txt_test['Text'].apply(
lambda x: " ".join([w for w in list(jb.cut(x)) if w not in stop_words]))
# 2.3、对训练集切词后的词语进行对整数的映射# * 先从训练集中找到最长句子的词长度max_length = max([len(s.split(' ')) for s in file_txt_train['Pre_Text']])
print(max_length) # max_length 会随着训练集的不同而改变
# * 获取分词器(只是用它做标记化处理)def create_tokenizer(lines):
tokenizer = tf.keras.preprocessing.text.Tokenizer(oov_token='<UNK>') # 多加一个未知词
tokenizer.fit_on_texts(lines)
return tokenizertokenizer = create_tokenizer(file_txt_train['Pre_Text'])
# * 使用 tokenizer.text_to_sequences () 函数来获取词语 - 整数编码# * 使用 pad_sequences 函数来为长度不够的文本进行填 0 操作,使所有文本长度一致# * 进行词语 - 整数映射def encode_docs(tokenizer, max_length, docs):
encoded = tokenizer.texts_to_sequences(docs) #词语 - 整数映射
padded = tf.keras.utils.pad_sequences(encoded, maxlen=max_length, padding='post') # 在结尾处补 0
return padded# * 转化为对应特征值和目标值的张量X_train = tf.constant(encode_docs(tokenizer, max_length, file_txt_train['Pre_Text'].tolist()))
X_test = tf.constant(encode_docs(tokenizer, max_length, file_txt_test['Pre_Text'].tolist()))
y_train = tf.constant(file_txt_train['Label'])
y_test = tf.constant(file_txt_test['Label'])
# * 注意:5 分类 不指定 num_class 时,num_class 的默认值是标签中最大数 + 1Y_train = tf.constant(tf.keras.utils.to_categorical(y_train))
Y_test = tf.constant(tf.keras.utils.to_categorical(y_test))
接着,开始构建模型。
针对本题,我构建的模型有一层嵌入层,两组卷积层、池化层和Dropout层,一层flatten层,两组全连接层。1、嵌入层:将处理好的词向量输入模型中
2、卷积层、池化层和 Dropout 层:卷积层,对词向量进行卷积,采用 3 核进行卷积,第一组选用了 32 个卷积核,以 relu 作为激活函数,第二组选用了 64 个卷积核。卷积层后紧接一层是最大池化层,后接一层 Dropout 层,随机使一定比例的神经元失活,提高模型的泛化能力。
3、flatten 层,将多维的数据一维化,作为卷积层和全连接层的过渡。
4、两组全连接层:作为分类器进行分类,后一个全连接层采用 softmax 函数,转化为 1*6 的张量(由于我先将标签使用了 to_categorical 方法转化,num_class 的默认值是标签中最大数 + 1),所以实现了 5 分类模型# 3、构建神经网络模型# 获取输入维度,即词典数input_dim = len(tokenizer.word_index)
# 构建模型def define_model(input_dim, max_length):
model = tf.keras.Sequential()
# 构建一个嵌入层model.add(tf.keras.layers.Embedding(input_dim=input_dim, output_dim=128, input_length=max_length))
# 构建一组卷积层、池化层和 Dropout 层model.add(tf.keras.layers.Conv1D(filters=32, kernel_size=3, activation=tf.nn.relu, padding="same"))
model.add(tf.keras.layers.MaxPooling1D(pool_size=4))
model.add(tf.keras.layers.Dropout(rate=0.2))
# 再构建一组卷积层、池化层和 Dropout 层model.add(tf.keras.layers.Conv1D(filters=64, kernel_size=3, activation=tf.nn.relu, padding="same"))
model.add(tf.keras.layers.MaxPooling1D(pool_size=4))
model.add(tf.keras.layers.Dropout(rate=0.2))
# 添加 flatten 层,转为一维张量model.add(tf.keras.layers.Flatten())
# 添加两组全连接层model.add(tf.keras.layers.Dense(128, activation=tf.nn.relu))
model.add(tf.keras.layers.Dense(6, activation=tf.nn.softmax))
# 配置训练方法model.compile(optimizer='adam', loss="categorical_crossentropy", metrics=["accuracy"])
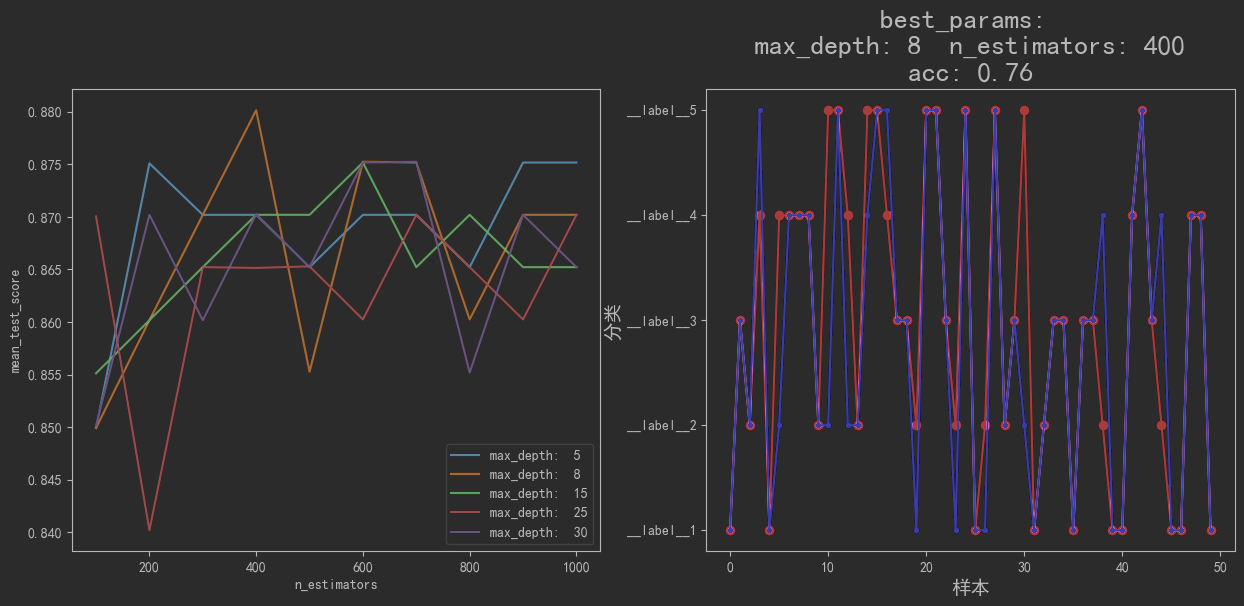
return model模型架构
![image-20230129161720966]()
然后,进行模型训练,保存模型,获取日志信息,以便画图。
注意:模型训练时,先划分20%作为验证集,用以查看模型的泛化能力# 4、进行模型训练def model_train(x_train, y_train):
model = define_model(input_dim, max_length)
# 训练,并获取训练的日志history = model.fit(x_train, y_train, batch_size=32, epochs=100, validation_split=0.2,
shuffle=True) # 再次划分 0.2 为验证集,不参与模型构建
# 保存模型model.save('temp_word_train.h5')
return historyhistory = model_train(X_train, Y_train) # 获取日志
接着,加载模型,进行模型评估
# 5、加载模型进行预测 | |
# 5.1、加载模型 | |
# temp_model = tf.keras.models.load_model ("./ 验证集 0.90 准确率的模型.h5") | |
temp_model = tf.keras.models.load_model("./temp_word_train.h5") | |
# 6、评估模型 | |
# 使用测试集来评估模型的准确率 | |
evaluate = temp_model.evaluate(X_test, Y_test, verbose=2) | |
print(evaluate) | |
# * 查看测试集中没有预测中的数据集 | |
pre_label = tf.argmax(temp_model.predict(X_test[:]), axis=1) | |
result = pd.DataFrame({"真实标签": y_test, "预测标签": pre_label}) | |
result[result["真实标签"] != result["预测标签"]] |
最后,通过画图来展示模型质量
根据模型对训练集的训练结果,来绘制loss值与迭代轮数的关系,准确率与迭代轮数的关系# 7、绘制分类图# 7.1、获取日志信息plt.rcParams["font.sans-serif"] = ["SimHei"] # 显示中文标签
plt.rcParams['axes.unicode_minus'] = False
loss = history.history["loss"]
val_loss = history.history["val_loss"]
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
# 7.2、绘制训练和验证集的损失值和迭代伦数、精确率和迭代轮数的图像plt.figure(figsize=(15, 10))
plt.subplot(221)
plt.plot(loss,color="blue",label="train")
plt.plot(val_loss,color="red",label="test")
plt.ylabel("Loss")
plt.legend()
plt.subplot(222)
plt.plot(acc,color="blue",label="train")
plt.plot(val_acc,color="red",label="test")
plt.ylabel("Accuracy")
plt.legend()
plt.subplot(223)
scale_ls = range(1,6)
index_ls = ['__label__1','__label__2','__label__3','__label__4','__label__5']
plt.yticks(scale_ls,index_ls) ## 可以设置坐标字
plt.title(f"acc: {round(evaluate[1],2)}", fontsize=20)
plt.plot(result["真实标签"].tolist(), color="red", marker='o', label="真实分类")
plt.plot(result["预测标签"].tolist(), color="blue", marker='.', label="预测分类")
plt.xlabel("样本", fontsize=14)
plt.ylabel("分类", fontsize=14)
plt.show()
![image-20230129162035008]()
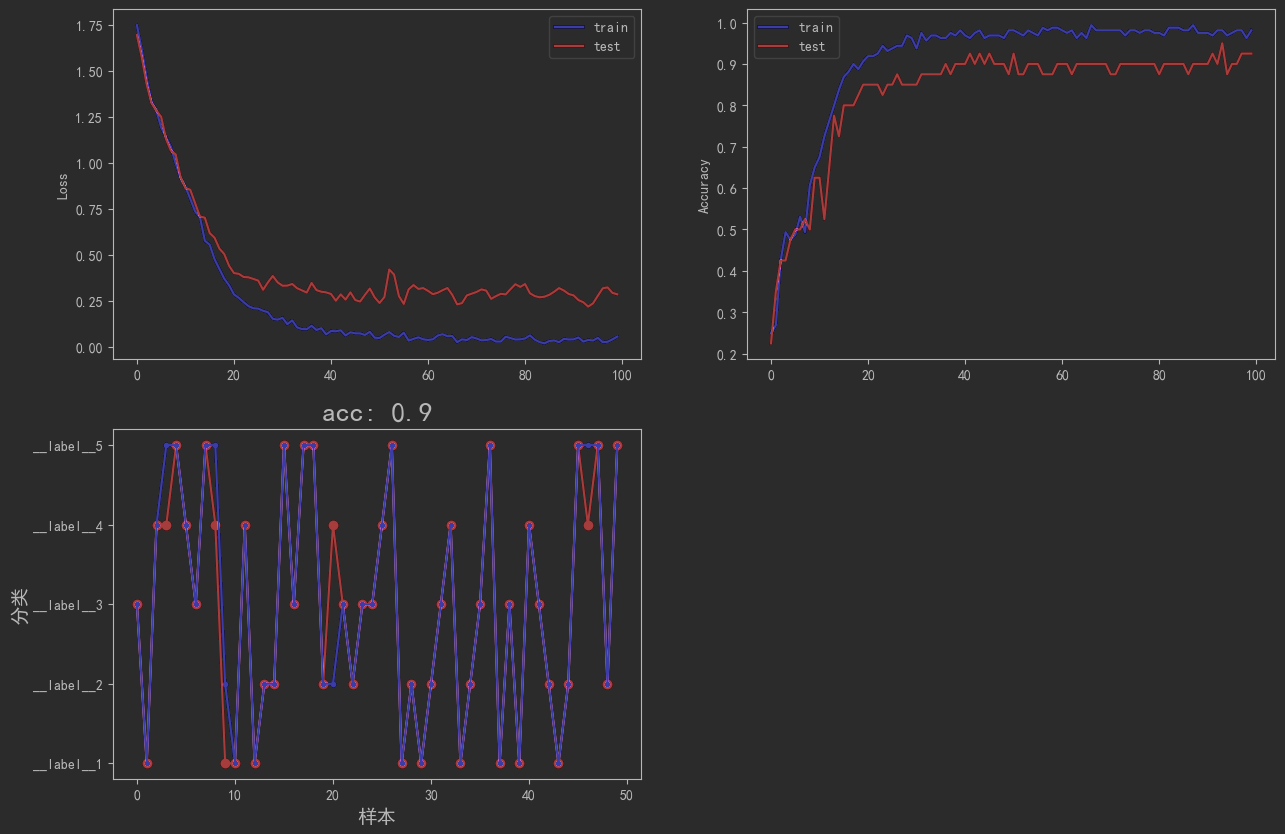
说明:上面两图中 test集 实际上又从 train集 种随机划分部分出来的作为 valid集 ,只有下面一幅图才是对 test集 的预测
从图中可以看出,该模型在测试集上的 准确率:0.9 ,而且模型在验证集上的 准确率稳定在0.88 。还不错。
而样本在迭代 40次左右 ,验证集的准确率的 损失函数值 就趋于稳定了,当 超过40次 时,还略微有上升的趋势。这说明,迭代次数 超过40次 ,容易出现过拟合,需要避免。
# 🔑FastText
FastText 官方文档:Automatic hyperparameter optimization · fastText
同样,首先导包
import pandas as pd
import jiebaimport randomimport fasttextimport matplotlib.pyplot as plt
接着,先获取数据,加载停用词
# 1、获取数据df_all_data = pd.read_excel(io="../src/gastric.xlsx", engine="openpyxl")
# * 加载停用词with open('../src/stop_words.txt', 'r', encoding="utf-8") as f:
stop_words = list(l.strip() for l in f.readlines())
stop_words.extend(['\n', '(', ')', ' ']) # 由于停用词中没有 '\n' 和中文的左右括号和空格,所以单独再加上去
然后,对数据进行预处理,随机打乱,简单划分成训练集、验证集和测试集。
fastText对文本输入有要求,需要进行预处理,因为默认前缀是__label__,所以要处理成将数据处理成fasttext可以处理的格式。如:__label__1,胃角 小弯 ……
# 2、数据预处理 | |
# * 将数据处理成 fasttext 可以处理的格式,如: __label__1, 胃角 小弯 …… | |
def preprocess_data_to_fasttext(pd_data, sentences, stopwords): | |
for _, row in pd_data.iterrows(): | |
temp = jieba.cut(row[1]) | |
temp = [k for k in jieba.lcut(row[1], cut_all=False) if k not in stopwords] | |
sentences.append('__label__' + str(row[0]) + ', ' + ' '.join(temp)) # 由于 Label 是整形,所以需要改为字符 | |
# sentences.append ('__label__'+str (row [0])+' '.join (temp)) # 由于 Label 是整形,所以需要改为字符 | |
print(row[1]) | |
result_sentences = [] # 存储分词后的所有种类的文本 | |
preprocess_data_to_fasttext(df_all_data, result_sentences, stop_words) | |
# * 随机打乱数据 | |
random.shuffle(result_sentences) | |
# * 简单划分训练集、验证集和测试集,并将数据保存至 txt 文件 | |
with open(file="./fasttext_train.txt", mode='w', encoding="utf8") as fw: | |
for sentence in result_sentences[:int(len(result_sentences) * .7)]: | |
fw.write(sentence + '\n') | |
with open(file="./fasttext_valid.txt", mode='w', encoding="utf8") as fw: | |
for sentence in result_sentences[int(len(result_sentences) * .7):int(len(result_sentences) * .9)]: | |
fw.write(sentence + '\n') | |
with open(file="./fasttext_test.txt", mode='w', encoding="utf8") as fw: | |
for sentence in result_sentences[int(len(result_sentences) * .9):]: | |
fw.write(sentence + '\n') |
- 接着,构建
FastText模型,查阅官网,发现可以 FastText 可以在指定时间内,自动调优寻找最佳f1分数,果断用它![image-20230129163129440]()
所以,以 train 集建立起 FastText 模型,设置训练时间为 60s
# 3、通过 fasttext 自动实现超参数优化,获取模型 | |
ft_model = fasttext.train_supervised(input='./fasttext_train.txt', | |
autotuneValidationFile='./fasttext_valid.txt', | |
autotuneDuration=60) | |
ft_model.save_model("./fasttext_model.bin") |
其次,加载模型(加载的模型,我选了另一个最好的,可调),进行模型评估和预测,并画图展示
注意:针对多分类问题,直接查看
fastText自带的精确率和召回率是一样的,都是准确率。
详细请见:为什么多分类计算出来的精确率 准确率 召回率 f1-score 值都一样? - 知乎 (zhihu.com)# 4、加载模型fasttext.FastText.eprint = lambda x: None
ft_model = fasttext.load_model("./fasttext_best_model.bin")
# 5、模型评估以及预测def my_test(filepath):
global ft_model,acc,number
""":param filepath: 需要测试的文件
:return: label_list: 真实分类 labels_predict: 预处理好的分类
"""
# 由于是多分类(该题每篇文本,仅仅属于某种分类,可以该文本仅有成唯一标签,所以 k=1)# 直接求整体的精确率和召回率都相当是求 预测正确的分类个数 / 总共的个数result = ft_model.test(filepath, k=1)
# 所以准确率 = 精确率 = 召回率acc = result[1]
number = result[0]
print('样本数量:', result[0])
print('准确率:', acc)
content_list = []
label_list = []
with open(filepath, 'r', encoding="utf-8") as fr:
for line in fr.readlines():
content_list.append(line.strip().split(",")[1])
label_list.append(line.strip().split(",")[0])
# * 预处理一下预测的标签标签值 使之与从测试集读取出来的 label 格式一致labels_predict = ft_model.predict(content_list)[0]
labels_predict = [i[:-1] for ii in labels_predict for i in ii]
return label_list,labels_predict
# 5.2、绘图plt.rcParams["font.sans-serif"] = ["SimHei"] # 显示中文标签
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(12, 10))
scale_ls = range(5)
index_ls = ['__label__1', '__label__2', '__label__3', '__label__4', '__label__5']
plt.subplot(311)
plt.yticks(scale_ls, index_ls) ## 可以设置坐标字
filepath = "./fasttext_train.txt"
label_list, labels_predict= my_test(filepath)
plt.plot(label_list, color="red", marker='o', label="真实分类")
plt.plot(labels_predict, color="blue", marker='.', label="预测分类")
plt.xlabel("样本", fontsize=14)
plt.ylabel("分类", fontsize=14)
plt.title(f"{filepath[2:-4]} number:{number} acc: {round(acc,2)}", fontsize=20)
plt.subplot(312)
plt.yticks(scale_ls, index_ls) ## 可以设置坐标字
filepath = "./fasttext_valid.txt"
label_list, labels_predict= my_test(filepath)
plt.plot(label_list, color="red", marker='o', label="真实分类")
plt.plot(labels_predict, color="blue", marker='.', label="预测分类")
plt.xlabel("样本", fontsize=14)
plt.ylabel("分类", fontsize=14)
plt.title(f"{filepath[2:-4]} number:{number} acc: {round(acc,2)}", fontsize=20)
plt.subplot(313)
plt.yticks(scale_ls, index_ls) ## 可以设置坐标字
filepath = "./fasttext_test.txt"
label_list, labels_predict= my_test(filepath)
plt.plot(label_list, color="red", marker='o', label="真实分类")
plt.plot(labels_predict, color="blue", marker='.', label="预测分类")
plt.xlabel("样本", fontsize=14)
plt.ylabel("分类", fontsize=14)
plt.title(f"{filepath[2:-4]} number:{number} acc: {round(acc,2)}", fontsize=20)
plt.tight_layout() # 解决标题重叠
plt.show()
![image-20230129163445544]()
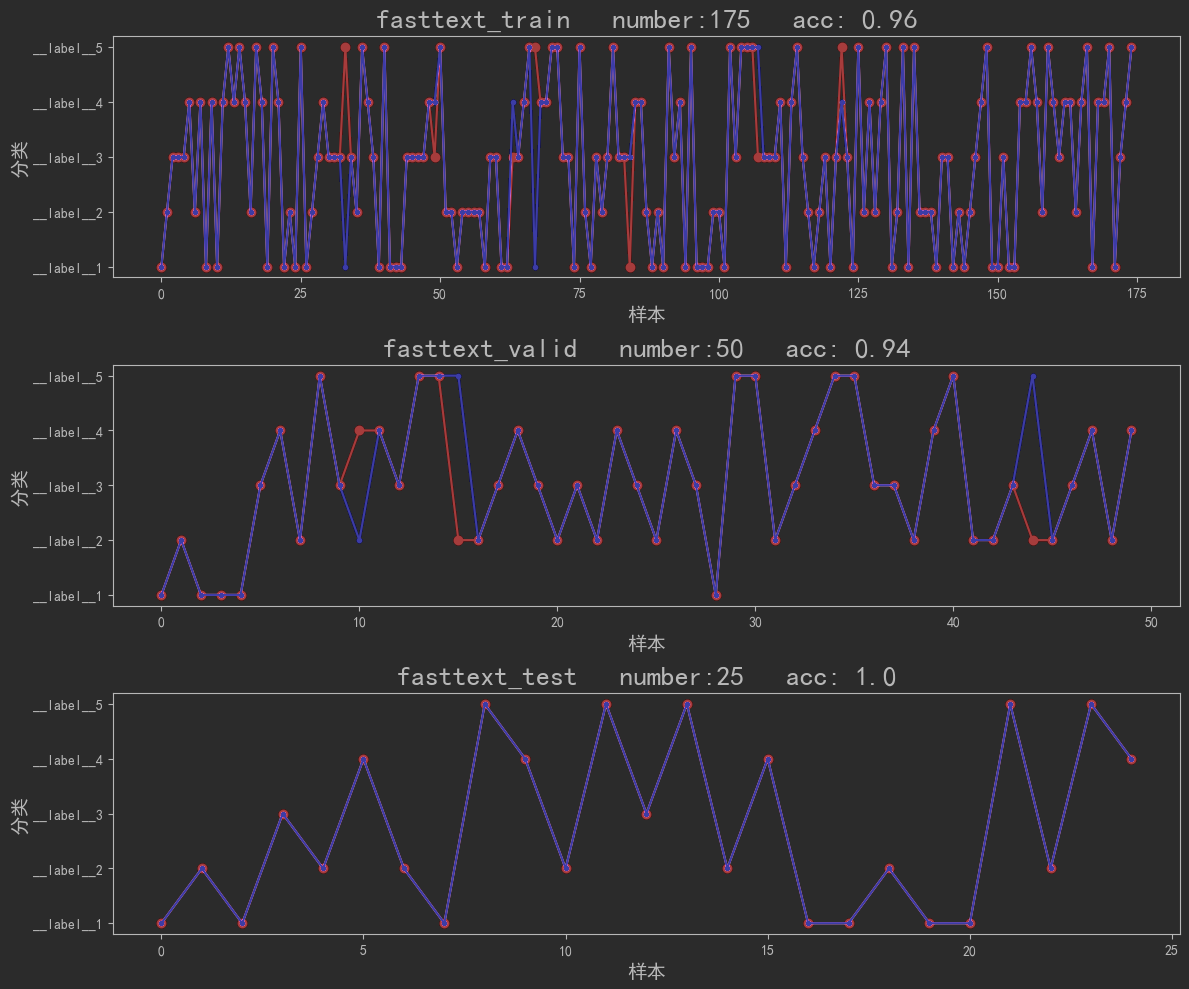
从图可以看出, fasttext 强者,竟如此恐怖如斯。在训练集上的 准确率达到0.96 ,在验证集上的 准确率达到0.94 ,在测试集上的 准确率达到1 。(当然,可能数据量过少了)而且,最重要的是,他还稳得很,构建很多次模型,测试集上得准确率基本保持在 0.9以上 。
# 🎒总结
可能是自己构建的 textCNN 模型中的词向量,单纯只是一个简单的整数映射,整数之间毫无关系,所以卷积效果不佳;也可能是由于数据量太少,准确率不稳定。
总之,还是 fasttext 更胜一筹。